AWS DeepRacerで楽しく機械学習を学んでみた!
みなさん、こんにちは!
エンジニアチームのだいじゅです!
梅雨の気配を感じ始め、今年はどんな夏にしようかと期待が高まる時期ですね。
昨今「機械学習」の進化が目覚ましく、あらゆる分野でAIが活躍しており、
私たちがパートナーとして提供しているAWSでも、様々な機械学習系サービスが展開されています。
どれも魅力的なサービスばかりですが、中には機械学習を専門とするエンジニア以外には理解が難しいサービスもあります。
ゆくゆくはそんな難易度が高いサービスを扱える様に成長していきたい!といった思惑の元、
弊社エンジニアの中でも機械学習初学者が集まって「AWS DeepRacer」を遊んでみたので、その様子をご紹介したいと思います!
#AWS DeepRacerとは
そもそもAWS DeepRacerって何でしょう?
AWS DeepRacerとは、機械学習(強化学習)を楽しく学べるAWSのサービスで、レーシングゲーム要素を含んでいます。
機械学習の中でも、「強化学習」を用いてレーシングカーをコントロールし、レースのレギュレーションによって、1周のタイムだったり、3周の合計だったりを競います。
では、どうやってコントロールするのかと言うと、強化学習によって仮想サーキットを走行させるための「学習モデル」を作成することによってコントロールします。
簡単に言うと、
サーキット上のどのルートをどのくらいのスピードで走行するかという情報を詰め込んだ「学習モデル」を作成し、より速く、正確にサーキットを周回することを目指します。
「学習モデル」を作成する過程で強化学習に触れることが出来るため、機械学習に触れたことがない人でもお手軽に学習を始めることができます。
# 学習モデルの作成
## 走行ルートの学習設定
強化学習で「学習モデル」を作成すると言っても、一体何を学習させればいいのでしょうか?
一般的に強化学習とは、エージェントが環境と対話しながらアクションを取ることで、報酬を受け取りその報酬を最大化するように学習する機械学習の一形態です。
AWS DeepRacerにおいて、
「エージェント」は「レーシングカー」に当たり、「環境」とは「サーキット」に当たります。
つまりレーシングカーが、
「走行して欲しいルートを走行すると報酬が高く」なり、
「走行して欲しくないルートを走ると報酬が低くなる」ように設定することが重要になります。
この設定は、「Reward function」に、Pythonコードで作成します。

当然ですが学習前のレーシングカーは、
サーキットを走り切るためには、どのようなハンドリングが必要かという情報を持っていません。
人間の様に視覚的にサーキットを見て、走行ルートを認識することも出来ません。
右に進んでみたり左に進んでみたりしながら、
何度もトライアンドエラーを繰り返して、
一番報酬が高くなるルートを蓄積して学習していきます。

## 走行速度の学習設定
走行ルートと並行して走行速度についても学習が必要です。
走行速度については「アクションスペース」で定義していきます。
アクションスペースとは、レーシングカーが取り得る行動パターンを決定するもので、
「ステアリング (ハンドル) の角度」と「速度」の組み合わせになります。
(速度は「アクセルを踏み込む強さ」と捉えた方が分かり易い)
例えば、「右に30度ステアリング (ハンドル)が傾いた時」には、
安定させるために「スピードを0.5」とし、
直進の時は「スピードを4(MAX)」とするといった設定です。
と言っても、「スピードを4(MAX)」と設定してもMAXスピードで走ってくれるという訳ではありません。
下の参考画像では、同じ角度に対して別の速度パターンが設定されていると思いますが、
この場合はどうなるのでしょうか。
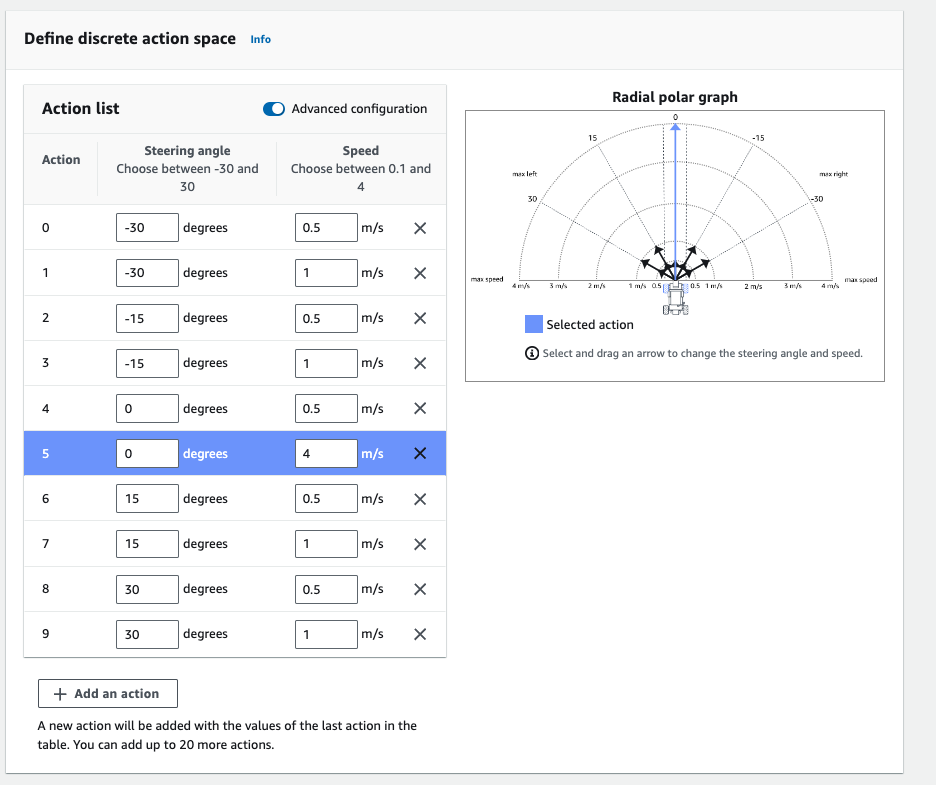
直進(Steering angleが0)時を例にすると、
レーシングカーがアクションを実行した時点で、
ステアリング(ハンドル)が0度(直進)であれば、
4か0.5かどちらかのパターンを選ぶことになります。
選択基準としては、より報酬が高くなるパターンを選択します。
(報酬関数の設定で、スピードでも報酬が変化する前提)
さらに、カーブで速度を出しすぎるとオフトラックやスリップの可能性が高くなることにも注意が必要です。
コースに最適なアクションスペースのパターンを設定し、学習させることが重要となりますが、
学習パターンが多くなるとそれだけ学習時間が長く必要となり、過学習の原因にもなります。
アクションパターンは最大で0〜29番の30個のアクションパターンが設定可能ですが、
学習時間との見極めが重要となります。
最適なパターンの組み合わせと、量を見つけるためには地道な検証が必要です。
参考として、下のサーキットでのモデル作成時の検証ポイントを記載します。

・右に30度のパターンを無くすなど、右に大きく曲がる様な不必要なパターンを無くす。
・直進はできる限り最大速度か、それに近しい速度にする。
・カーブにおける最低速度をどこまで上げられるかを探る。
・過学習にならない様に学習時間は計2〜4時間にして、その場合の適量のパターン数を探る。
・設定した角度について、どのくらいの間隔がベストか探る。
アクションスペースの決定は地道なもので、
スピードの値が0.1変わるだけで全然違う動作になったり、組み合わせによっても変化があるので最適なものを見つけるのに時間がかかりました。
## 学習時間
最適な学習時間は、報酬関数やアクションスペースの設定にかなり影響を受けます。
そのため適切な学習時間を見極めるためには工夫が必要です。
私達は予め、学習時間を2〜4時間程度の幅で固定し、
基本は設定値を変更しながら適切な組み合わせを探していきました。
私達の検証では、
1回目の学習は2〜3時間行い、ある程度の方向性を学習させた後、
微調整として1時間程度の学習を行う方法がより良い成果を上げました。
良いモデルが作れたという判断は、学習中に表示されるReward graphが参考になります。

表の赤い線が、獲得した報酬レベルを表しており、
より高い%に推移したタイミングで、学習が完了する様に調整が必要です。
学習時間面での注意点として、
120分の学習時間ではベストモデルだったのに、
140分ではベストモデルではなくなってしまうという事が発生します。
長く学習すれば良いというものでもなく、
グラフと設定内容を検証し、見比べながら調整していく事が、
優秀なモデルを作成するための鍵となります。
#チームで触ってみた感想
最初は全員が手探り状態から始まりましたが、検証する役割を決め、
各々が調べてきた情報を共有して「〜できそう」とか「この設定値をいじったら走りが安定するっぽい」と言い合いながら仮説立てと検証を繰り返しました。
検証中には、スピードが速すぎてコースを逸脱しまくるものが出来てしまったり、
逆にスピードは遅いが、安定したルートを走るものが出来たりと、様々な結果に遭遇しました。
メンバー全員が、担当する領域で仮説立てと検証を行い、改善を繰り返した結果、無事に目標タイムを切る「機械学習モデル」が完成しました。
個人で出す成果はもちろん大切ですが、チームプレーで素早く成果を残すことが私たちの強みです。
弊社で大切にしている価値観の一つにフロンティアスピリッツというものがあります。
変化を恐れることなく、開拓者精神で挑み続けるという価値観です。
今回の挑戦はまさしくその精神を体現した取り組みとなりました。
私達の飽くなき探求は続きます!
皆様もぜひ一度AWS DeepRacerで遊んで、機械学習に触れてみてはどうでしょうか!
それでは、また次のブログでお会いしましょう!
RECOMMEND






